

Ontologies and domain modelling
An account by Conrad Taylor of the 20 September 2018 NetIKX meeting.
Speakers — Helen Lippell, Silver Oliver, Michael Smethurst
Introduction: meanings of ‘ontology’,
from metaphysics to information science
An explanatory foreword by Conrad Taylor
IN PHILOSOPHY, ontology is a branch of metaphysics — the application of analytical thinking to basic questions of existence. In the Greek world, this line of enquiry started with the pre-Socratic philosophers of the sixth century BCE who asked themselves what it means for something to exist, what things are made of, the nature of space and time, what preserves the identity of objects even when they undergo change, and the nature of cause and effect.
Within this agenda, ontology (ὄντο + λογία – ‘discourse about being’) focused on what it means for things to exist, to be ‘entities’. Philosophers set out to categorise different kinds of entity, often in a hierarchical set of relations between classes of thing. See for example the third century diagram called ‘Porphyry’s Tree’, which had enormous influence in mediaeval thought, and later shaped Linnaeus’ biological classification according to Kingdom, Phylum, Class, Order, Family, Genus and Species.
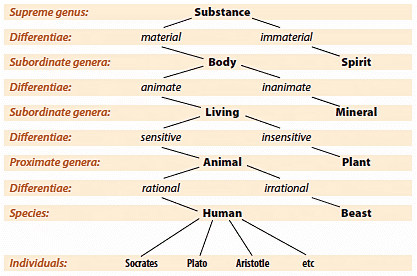
A representation of Porphyry’s Tree. Diagram art by Conrad Taylor.
IN INFORMATION SCIENCE, the term ‘ontology’ has been appropriated to refer to a human artefact instead: specifically, a rigorously defined vocabulary and set of rules, used to describe entities, concepts and the relationships between them, within some domain of activity or study. Some examples of ‘domains’ in which ontologies have been fruitfully applied are — particle physics; chemistry; biological and medical science; law and regulation; the properties and applications of metals and alloys; commerce; finance.
Ontologies are used to organise knowledge in medical informatics (e.g. SNOMED Clinical Terms); in geography (by Ordnance Survey); by groups like Lockheed Martin, General Motors and NASA who have complex systems to document; by governments, and the military. Thus, in hijacking the term from metaphysics, information workers have converted ‘ontology’ to mean something very practical – and surprisingly down to earth, when it’s properly explained.
Helen Lippell on ontologies and their uses
OUR FIRST SPEAKER, HELEN LIPPELL, is a NetIKX member. She describes herself as a freelance taxonomist, and is an organiser of the annual Taxonomy Boot Camp London conference. She also works with organisations on constructing thesauri, ontologies, and linked data repositories.
Helen’s passion is ‘organising stuff’ to make it easier to access and work with information. She also likes technology, and ‘building things’. As far as she is concerned, the point of ontology construction is to model the world, so as to help to meet business objectives, and that’s the practical angle from which she approached the topic.
Ontologies ‘versus’ taxonomies etc.
Taxonomies and ontologies are quite strongly related. The difference, said Helen, is that while taxonomies are concerned with the relationships between the terms used in a domain (also defining which are broader, which narrow, which are equivalent and which are preferred), ontologies focus more on describing the things within the domain, and the relationships between them. The idea of mapping a domain and then constructing a model of it is something that Silver Oliver and Michael Smethurst would describe and demonstrate later in the afternoon.
Compared to taxonomies, ontologies aspire to greater rigour in the semantic rules which tie entities together, and to a degree of logical formalism which, ideally, lets machines join us as partners in navigating the web of relationships and meanings, though the construction of ontologically founded Description Logics and the application of machine reasoning which follows those logics.
(The account of a 2005 lecture by Professor Ian Horrocks called ‘Ontologies and the Semantic Web’ is a good place to look for a more detailed but very readable explanation of how the quest for machine reasoning has led to ontologies, description logics such as SHOIN, and the Web Ontology Language OWL. Download the PDF from here.)
Taxonomies, ontologies – neither is inherently better: you choose what is appropriate for your business need. An ontology offers greater capabilities, and a gateway to machine reasoning, but if you don’t need those, the extra effort will not be worth it. The two can also be combined, where the ontology gives you the structure and the classes and allows for interoperability with other data sets, and the taxonomy provides the controlled vocabularies which help with navigation and search.
A more recent Web standard which can help in formally representing taxonomies and other classification schemes in a readily shareable way (as Linked Data) is SKOS – the Simple Knowledge Organization System. This got a couple of brief mentions during the afternoon, but here wasn’t time to delve deeper.
Some definitions
Class: this is a central concept in ontology work. A class groups together a set of things which have properties in common (at least one property, ideally more). Example: the class of ‘domestic cat’ (Felis sylvestris catus) groups together millions of individual cats around the world.
Because an ontology is designed to be functional within a particular domain of practice – it’s a business tool – different groups will define classes differently to match their purposes, even if they describe the same sort of thing. Helen’s example was that an ontology of animals for managing a zoo will require very detailed information on different species of animal. But if you’re running a pet shop, you can get by with a handful of categories of animal.
Subclasses are also recognised in an ontology. (Gerbils and guinea-pigs are both rodents, and all rodents are mammals.) But ‘subclassing’ is not a matter of simple mono-hierarchies: cats are mammals, boas are reptiles and owls are birds, but all also belong to the class of obligate carnivores.
Instances is a term used to denote the individual members of a class. (‘Bilbo Baggins’ is an instance of the class of hobbits; The Battle of Lincoln, 1217 is an instance of the class of military conflicts.)
Relation or relationship: this refers to what links the different entities, whether those entities are instances, classes, or concepts. These can be as broad or as detailed as your business purposes demand. Helen confesses that quite often she just makes do with a relationship statement such as ‘is a [member of class]’, or ‘has’:
— guinea pig [is a member of class] rodent
— Charlie [is a member of class] guinea pig
— Guinea pig [has] fur
(The reader may note that the above statements are strongly aligned with the concept of RDF triples, the three-part subject–predicate–object statements which are used in Linked Data and other Semantic Web applications.)
strong>Inverse relationships are those which can be read in both directions (‘Patty is the sister of Suzy’). Other relationships are reversible but with inversely matching terms: parent and child for example. And if the aim is to support machine reasoning such as in search and discovery, the ‘stupidness’ of machines may require any derived description logics to have more elaborate rules e.g. HasUncle = HasParent (who) HasBrother.
Attributes: these are properties of the entities, or indeed properties of the relationships (because relationships can also be treated as entities). Attributes might record features of the entity, characteristics, or parameters such as permissible data type (an example of a data type parameter for a credit card number is that it must consist of 16 digits). One attribute could be cardinality, where you specify whether an entity can be linked to multiple values, or there must be only one (a place might have a Welsh and an English name, but can have only one OS map grid reference).
(As we were later to discover in our exercises, it can be hard to decide what should be an Attribute and what is better represented as a Relationship to another Class.)
Ontologies and the Semantic Web
The information science version of ontologies didn’t come from nowhere: it is related to other efforts to construct the Semantic Web. Consider the knowledge graph concept – in many ways, this is a synonym for ontology, carrying with it a reminder that a graphical image of blobs linked with lines (a form of network diagram) is quite common as a way to represent an ontology, and one we would soon be using in our NetIKX table exercises.
The term ‘Knowledge Graph’ (thus capitalised) is also Google’s name for an extension to its search engine service. This gathers structured data from publicly available sources such as Freebase, Wikipedia, Wikidata, Spotify and the CIA Factbook, and supplements Google search reports with an ‘infobox’ panel to one side containing summary ‘facts’ (though critics point out that Google neither verifies its sources nor lists them). Such a service can operate only because public shared ontologies have been created to classify and link the data.
Schema.org is a community project initiated by search giants Google, Bing and Yahoo, and latterly Russia’s Yandex, which provides structured ways for content providers to mark up and share their data, using standardised namespaces, and using one of three approved markup methods – Microdata, RDFa, or JSON-LD. Helen encouraged us to find out more about this, if our jobs involve working with information on the Web.
Uniform Resource Identifiers (URIs) are another important Semantic Web concept. The kind of URI that most people will be familiar with most is the URL, Uniform Resource Locator, which identifies a location on the Word Wide Web where a resource can be found. Another kind of URI, not as widespread in use, is the Uniform Resource Name (URN). URNs are intended to be more persistent, location-independent resource identifiers, registered with a curating authority: ISBN and ISSN numbers for books and journals are example in frequent use.
Dereferenceability of URIs is important in Semantic Web work. This means that software with access to the Web can take the URI, fire off a query which accesses the online resource, verify it, and use it.
Linked Data is a subject much discussed these days in knowledge organisation and information management circles. (It was the subject of a whole day’s conference of ISKO UK in September 2010, and recordings of the eleven talks are all available on line at http://www.iskouk.org/content/linked-data-future-knowledge-organization-web.) Ontologies are helpful in Linked Data work, especially standardised and publicly shared ones, because they enable links between different data sets, identifying which entities, classes and attributes ‘mean the same thing’ in both places.
Helen apologised that she did not have time to delve into other important aspects of how ontologies and semantic modelling are implemented, such as the Resource Description Framework (RDF) and its ‘triples’ method of defining facts and relations; the W3C’s Web Ontology Language (OWL); and the SPARQL method and language for constructing queries. (Some of these are addressed in the Horrocks paper cited above.) Instead, she wanted to move us from the domain of the theoretical, to examples of where ontologies are being used to get real valuable work done.
What are ontologies for?
Helen listed a number of business scenarios in which ontologies can be helpful – information retrieval, classification, tagging, data manipulation. She is doing a lot of work currently on an ontology that will help in content aggregation and filtering, automating a lot of processes which are currently manual/mental.
Linking data – especially linked open data (LOD): this may not be as trendy as a few years ago, but there are a lot of useful LOD-based applications out there. If you have an internal business information process and you want to link open data sources to it, you need a reliable way of mapping from your own data structures to the external ones. Established and standardised ontologies can provide that bridge. (For more detail about Linked Data, see the excellent presentation given by Dave Clark to NetIKX on 25 January 2018: http://www.conradiator.com/kidmm/netikx-graph-linked-data.html.)
Some use cases from Helen’s career…
- A London listings magazine wanted to automate restaurant recommendations within an online app; the project created an ontology and linked algorithms. The criteria for recommendations took into account proximity, plus what kind of food, atmosphere, price range and so on the user preferred. Concepts were also linked in such a way that, for example, if someone had searched for Vietnamese restaurants, then Korean and other East Asian cuisines might additionally be suggested.
- An educational publisher is seeking to move away from the old textbook model for managing and presenting its content. At the same time, they want to get rid of a plethora of earlier-generation content management systems. This ongoing project aims to achieve a single content management platform, linked to a single ontology. This is helping to establish, for example, strict definitions for parts of books and parts of courses; outsourced digital assets such as stock photography; arrangements for content re-use; and associated rights management issues.
- A news agency wanted to get journalists to populate fields of metadata relating to the news stories it was curating – but with a user interface that would hide the complexity of what lay beneath! Helen worked on the UI aspect of the system, which incorporated Linked Data features. For example, if a journalist noted that a story had something to do with Doug Engelbart, the system would retrieve structured information about him from DBpedia, and also search across the agency’s own multimedia databases to pull in links to images, video etc.
- A video game producer surprisingly took up ontologies big time. Their ontology is around the domain of the video game: for a given title, it applies a model about which platforms it runs on, if it is part of a larger franchise, if there are special editions, who are the characters, what weapons you can buy ‘in game’, and so on. Their aim is to drive personalised content, and to intervene with pop-up suggestions: if you are stuck on a level, the game could suggest a weapon or tool you could buy to get you further on. Ultimately, of course, the aim is to make money from the gamers.
Implementation and tools
Implementing an ontology project is not trivial. It starts with a process of thoroughly understanding and modelling everything connected to the particular domain in which the project and business operate, and from those users’ perspectives. Information professionals are well suited to be the bridge, on such projects, between people with those technical skills, and others who probably have a clearer focus on what the business needs are – and who can also involve and advocate for the end-users of these systems.
Software is available to assist in building and managing an ontology as it develops. The best-known is Protégé, developed at Stanford University [http://protege.stanford.edu/], This is very capable and free of charge, but it has a complex user interface and usually requires customisation. Another free offering is VocBench [http://vocbench.uniroma2.it/], developed originally for the communities around the UN Food and Agriculture Organization.
Vendors of taxonomy tools are starting to venture into support for ontologies. Synaptica LLP recently brought out its Graphite tool [https://www.synaptica.com/graphite/]; and there is support within PoolParty [https://www.poolparty.biz], though at present this lacks visualisation support.
Exercise (in table groups)
Sheets of flip-chart paper and marker pens were distributed to the table groups. We were asked to choose a subject, either from a supplied list or invent our own. Within that ‘domain’ we were to draw and label circles to stand for concepts, and draw lines to link them with (named) relationships. We could add attributes if we wanted to get fancy! Helen’s advice was – if we started to get stuck, the best way to move forward is to imagine a context of use – how might the existence of the model help meet a business or user need?
- Three of the table groups chose to work on the suggested issue of ‘London’. Part way in, they all stopped and asked – heck, what’s he purpose here? Who are we doing this for? Two of the groups decided they were trying to guide visitors to London; the third chose to support a five-year ecology plan for the capital. Of course, these different purposes led to different ontologies.
- One of the ‘visitor-oriented’ groups drew classes for places, things to do, and transport. Helen noted that this group had drawn a Class circle for ‘destination’, then crossed it out again. The group explained that this early idea turned out to be too broad – everywhere can be a destination; why, London itself is a destination. The concept wasn’t granular enough to be useful.
- One of the ‘London’ groups pondered on the many forms of Relationship possible. Dion Lindsay said they could be ‘typed’ through labels such as ‘eats lunch at’ – ‘travels to’ and so on. This group also felt constrained by the 2D physical paper form, and wished they could model the diagram in three dimensions with links made of string! (Note: this is where software can help with various kinds of visual filters, such as temporarily hiding all relationships except those of a defined type, or colourising them by category.)
- A fourth table group, which included people from the Health and Safety Executive, chose to make an ontology to support HSE inspectors in the field with their information needs.
- The fifth table, and this was the one I worked on, started on an ontology of classical music, as it might be required by a radio broadcaster curating a large digitised playlist collection. Classes here included Composer, Genre, Performer, Instrument(s). Then we added sub-classes including Works; and, a Manifestation of a Work (such as András Schiff’s 2008 recording of J. S. Bach ‘48 Preludes and Fugues for the Well Tempered Clavier’, N0. 1, Fugue in C major, BWV 846). That Manifestation in turn gets attributes such as date, place, performer(s).
Our group was unsure in which direction relationships should flow. Does a Composer create a Work, or is a Work created by a Composer – or is the link two-way with complementary opposites? Claire Parry, who reported from this table, added that you can see the richness of links by looking at the categories at the bottom of a Wikipedia article. (Example: András Schiff is in 22 Wikipedia Categories including ‘1953 births’, ‘Hungarian exiles’, ‘Jewish classical pianists’ and ‘living people’.) - Several exercise groups reported that they had had difficulty deciding what counted as a Class; and when something was best defined as a Sub-class, and when as an Attribute.
Resources recommended by Helen Lippell
- Practical Ontologies for Information Professionals —
Book by David Stuart; Facet Publishing (2016); 224pp; £64.99 - An Introduction to Ontology Engineering —
Free PDF textbook by C. Maria Keet; self-published (2018); 270pp - Taxonomies and Ontologies —
LinkedIn post by Andreas Blumauer (PoolParty); (2017) - Why ‘Ontology’ will be a big word in your company’s future —
Forbes magazine article by Kurt Cagle (Semantic SEO Solutions); (2018)
Silver Oliver: introducing domain modelling
Silver Oliver is an information architect who has recently been working with Michael Smethurst and his colleague Anya Somerville at Parliament. Silver announced that our second session would be similarly organised to the first, with a short talk and a practical exercise.
Why should we be talking about domain modelling in a workshop on ontologies? Because, said Silver, there is too often a tendency for people to jump into trying to construct an ontology model, perhaps in Protégé or some other tool, when they should be spending time up front having conversations about the domain. Domain modelling is fundamental to compiling successful taxonomies, controlled vocabularies and classification schemes as well as formal ontologies.
An ontology is just one form of representation for information; and a project often moves between several forms of representation. For example, the BBC Music project consumed Linked Data from MusicBrainz, in JSON; it published RDF; the data was stored relationally. BBC Sport consumed XML and stored data as RDF. UK Parliament is consuming relational data, and both storing and publishing in RDF, amongst other formats. Despite these different tool systems and representational forms, it’s the domain model that establishes the shared understanding in the first place.
When you set out to model a domain, it’s beneficial to engage as many voices and perspectives as possible. That’s another reason for holding back from exploring tools and implementations, because if you start to tinker with these, you ‘get technical’ too quickly, and thereby exclude people from being able to participate with their views.
Domain-Driven Design
Domain-Driven Design – this idea comes from Eric Ewans, and his book of the same title. Ewans worked on air traffic control systems, in which context he noticed developers thought they could have a quick chat with the subject matter experts, grasp how air traffic control works, and then immediately start to model and build relational data schemes. Wrong!
Ewans’ insight was that you should collect everyone who can contribute to a design decision, cloister them together, and keep them ‘drawing back at’ each other (temporary and fluid whiteboarding) until everyone emerges with the same model in their head. It’s a good idea to make your initial mistakes early on a whiteboard, when recovery is cheap!
Here is some suggested reading about Domain-Driven Design:
- Presentation about DDD by Brett D. Roads: https://www.cs.colorado.edu/~kena/classes/5448/f12/presentation-materials/roads.pdf
- Also InfoQ summary at http://carfield.com.hk/document/software%2Bdesign/dddquickly.pdf
Michael Smethurst directs our second exercise
Michael used to work with Helen Lippell and Silver Oliver at the BBC, and now works at Parliament with Anya Somerville and ‘bits of’ Silver as the external consultant. In their domain modelling work for Parliament, they don’t use Protégé – they use text editors, whiteboards and paper. Actually, as far as he’s concerned, the technology part isn’t as interesting as the knowledge acquisition, and the conversations you need to have to capture it.
Michael warned us in advance that workshop settings like ours are a really bad way to do domain modelling! It’s better to hold smaller group conversations, and collate the results over time. Silver added that small group work brings out the contributions of quiet people in a way large gatherings can’t. Another powerful technique is to draw out anecdotes.
Michael’s exercise brief: ‘Imagine you are working for a broadcasting organisation, which makes programmes themed around food and recipes. The broadcaster wants to use its collection of recipes to make a Web site. We are going to domain-model the food, the processes and the recipes.’
The first exercise task was: take Post-It notes and compile a collection of all the types of person you would want to go and talk to, for knowledge acquisition purposes. We do this so that in the following stages of investigation, you get as many perspectives as possible. This task gets revisited, because your ongoing interview process will turn up suggestions of other people whose views should be consulted and stirred into the broth.
The second task: Next we were to use sticky notes again to brainstorm lists of all the types of things, the entities or classes within this domain space. Some of the ‘things’ would be people already identified in the first round (e.g. chefs), but what what would the others be? From this stage, you want to gather in the contributed notes and start to organise them into groups. This helps you to infer what the classes and sub-classes are.
Pooling and grouping
Ideally you would collect the contributed fragments on a big substrate area on which you can draw, e.g. to add lines that ‘corral’ suggestions into category groups, or to draw connecting lines. A group of seven or fewer people in a group would be ideal: in that case you could cover a rectangular table with ‘lining paper’ from a DIY home decorating store (£20 will get you a 15-metre roll of high-grade metre-wide lining paper from B&Q), and you can all stand around it, shuffling cards or Post-It notes into place.
In our case, with about forty bodies in the room, a vertical display at the end of the room was necessary. A large whiteboard would have been ideal, but we had only the wall of the meting room available; so, no drawing lines! Another drawback to the exercise, compounded by room geometry and pressure of time, was that Michael and Silver did the arranging and grouping ‘for us’, which left us rather marginal to these decisions.
They found that a number of concepts could be clustered into a ‘dietary’ category – ‘gluten free’ or ‘vegan’ for example. Another category was about types of meals, such as ‘supper’ or ‘lunch’. There were also sub-classes of courses within a meal, such as ‘deserts’ or ‘starters’. There were meal associations with festivals (Christmas, Eid al-Fitr, Thanksgiving, Burns Night could be examples); birthday celebrations are similar. There are cultural and regional associations (couscous, bierwurst, pizza, fufu…). Other strong categories were for ingredients, for cooking and preparation methods, cooking utensils etc.
Some people contributed ideas such as ‘video and audio’, ‘photography’ and ‘ratings’. Michael argued that we were running too far ahead, thinking of Web site presentation and publishing, rather than exploring the domain of food and cooking per se.
Michael admitted that the afternoon’s exercise wasn’t coming out with the kinds of results he had expected. Normally when he runs this exercise, a sense of centrality tends to emerge around concepts such as ‘ingredients’ – ‘chefs’ – ‘recipes’ – ‘methods/steps’ and then some other classes around the edge. He accused us of sabotaging the exercise by being a bunch of librarians too fond of classification schemes!
Part three: building the links. Once a suitable set of entities have been brainstormed, the next step is to investigate what ties them together. So, you can say that a chef has a recipe, and that a recipe has ingredients, and also has method steps.
People, roles and ‘time boundness’
In the case of concepts of ‘chef’ or ‘cook’, Michael noted that what at first appears obvious as a category may benefit from further deconstruction. ‘Jamie Oliver’ is an instance of ‘chef’, but what of ‘Two Fat Ladies’? In domain modelling, it is often smarter to establish a more general concept such as in this case ‘agent’, which can be subclassed into individuals and groups, and each subclass further elaborated with attributes.
In their Parliamentary domain modelling work, Michael and Anya must cope with situations in which one has to distinguish between the person (e.g. John Bercow) and the rôle (e.g. Speaker of the House of Commons). This can be solved with the concept of incumbency, qualified with attributes of time-boundness: thus, Bercow has been the incumbent of the rôle of Speaker since June 2009.
Time-boundness can also apply to a person’s name, which can change during their lives, or they may acquire additional ones – by deed poll, by marriage, by ennoblement. Gender identity can also change. Michael said that ‘naïve’ domain models often over-rely on attributes: it’s better to make ‘Name’ a class, he suggested, with time-boundedness as an attribute.
Silver sums up
Silver Oliver closed the session with a set of recommendations:
- Don’t dive into software: start with whiteboards!
- Don’t work alone as the data modeller in the corner – domain modelling is all about understanding the domain, through conversation and building shared language.
- Be wary of getting inspiration from other models you believe to be similar — start with the conversations instead (though stealing ideas can be useful).
- Rather than ‘working closed’ and revealing your results at the end – keep the processes open, and show people what you are doing.
- An evolving ontology of the domain is a good way to capture these discussions and agreements about what things mean.
- Rather than evolving a humongous monolithic domain model which is hard to get your head around, work with smaller domains with bounded contexts.
At which point, refreshments seemed like a good idea.